2023年,ChatGPT席卷市场,为AIGC点燃燎原之火。经过数月发酵,OpenAI于近日发布多模态预训练大模型GPT-4,微软紧随其后推出接入GPT-4的Office全家桶,百度发布AI大模型“文心一言”……
作为近期科技圈的“顶流”,AIGC(AI Generated Content,人工智能生成内容)并非“新秀”。

AIGC发展历程可以分为3个阶段,以“图灵测试”为代表性事件的早期萌芽阶段(20世纪50年代至90年代中期)、从实验性向实用性转变的沉淀积累阶段(20世纪90年代中期至21世纪10年代中期)、依托生成式对抗网络GAN等技术及算法的快速发展阶段(21世纪10年代中期至今)。
随着AI生成的发展趋势朝着多模态演进,AIGC正在带来新一轮的科技和产业革命。新的机遇下,我国基于丰富的产业需求和应用场景,既要加快攻关关键技术、鼓励发展创新应用,同时也要推动安全治理前置,在全球科技变革之际,抢占赛道。
AIGC风险图谱及监管体系
新兴技术都会经历从野蛮生长到安全合规的过程,AIGC同样不可避免。当前,AIGC所带来的安全风险成为重点议题。
作为AI应用发展的重要分支,AIGC的风险既包括AI伦理风险,也包括其特定算法应用所带来的新型风险,比如更多的隐私保护忧患、智能代替人工造成的就业担忧、算法对于市场竞争带来的不公平以及著作权侵权等。
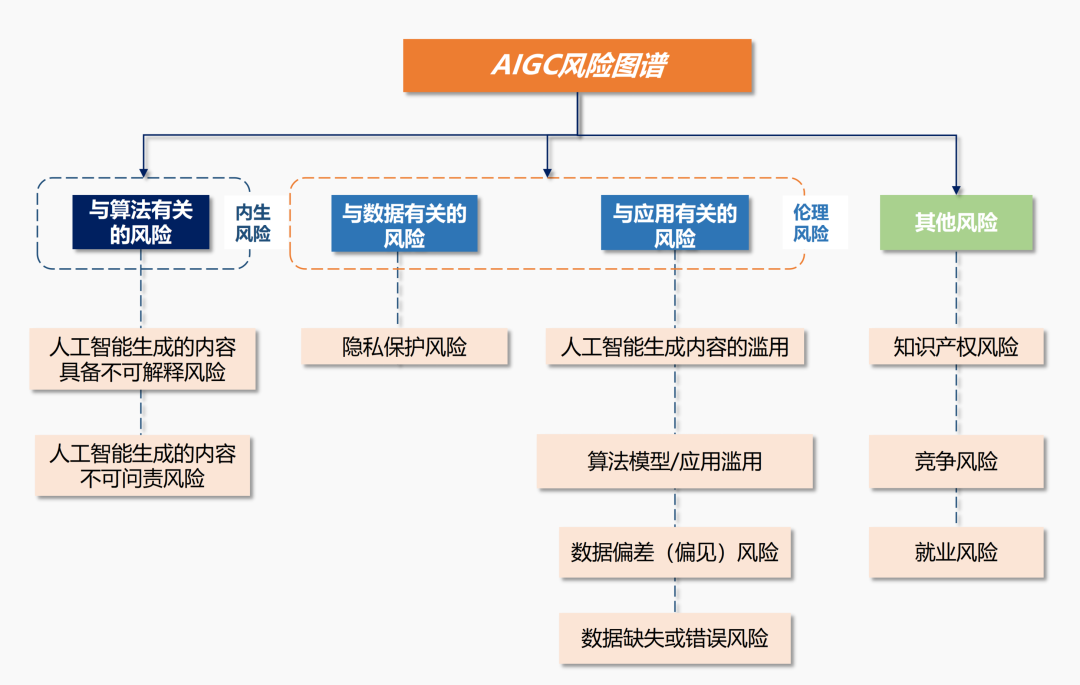
聚焦AIGC存在的风险,我国现有的监管体系已经成形。2017年以来,我国先后发布一系列人工智能产业促进政策,推动人工智能技术创新和产业发展。
随着人工智能的广泛应用与实践,我国对于人工智能的监管重点也从“发展”扩展到“AI伦理安全”“算法治理”等问题上,虽然针对AIGC专用数据集、算法设计和模型训练的监管仍然有待完善,但整体框架体系已经具备。

从人工智能监管部门来看,我国呈现多头监管的现状,有关部门包括国家市场监督管理总局、国家互联网信息办公室、工业和信息化部、科技部等。
在法律法规层面,一方面是通过专门性综合性立法对网络运营者在使用人工智能技术的义务和责任进行规范,另一方面则是切实聚焦到人工智能领域的算法、模型、技术,进行具体规范。

2021年,先后发布的《关于加强互联网信息服务算法综合治理的指导意见》《互联网信息服务算法推荐管理规定》从算法治理的角度,对算法使用过程中的安全监测、算法评估以及算法推荐对个人信息主体带来的影响等内容进行规范。
根据《规定》,算法推荐服务提供者应当在提供服务之日起十个工作日内通过互联网信息服务算法备案系统(已经上线)进行备案(包括提供服务提供者的名称、服务形式、应用领域、算法类型、算法自评估报告),且完成备案后需在对外提供服务的网站、应用程序等显著位置标明备案编号等信息,目前已有百余家企业完成备案。
2022年,国家网信办、工信部、公安部联合发布的《互联网信息服务深度合成管理规定》则聚焦“深度合成技术”“深度合成服务”。根据定义,深度合成技术,是指利用深度学习、虚拟现实等生成合成类算法制作文本、图像、音频、视频、虚拟场景等网络信息的技术。这一定义与AIGC的定义(人工智能生成文本/图像/音频/视频等多模态内容)高度吻合,因此该规定可以视为规范AIGC技术及服务的重要参考。此外,在这一规定中,对于深度合成服务提供者、深度合成服务使用者、深度合成服务技术支持者三个主体的责任义务也作了进一步明确。
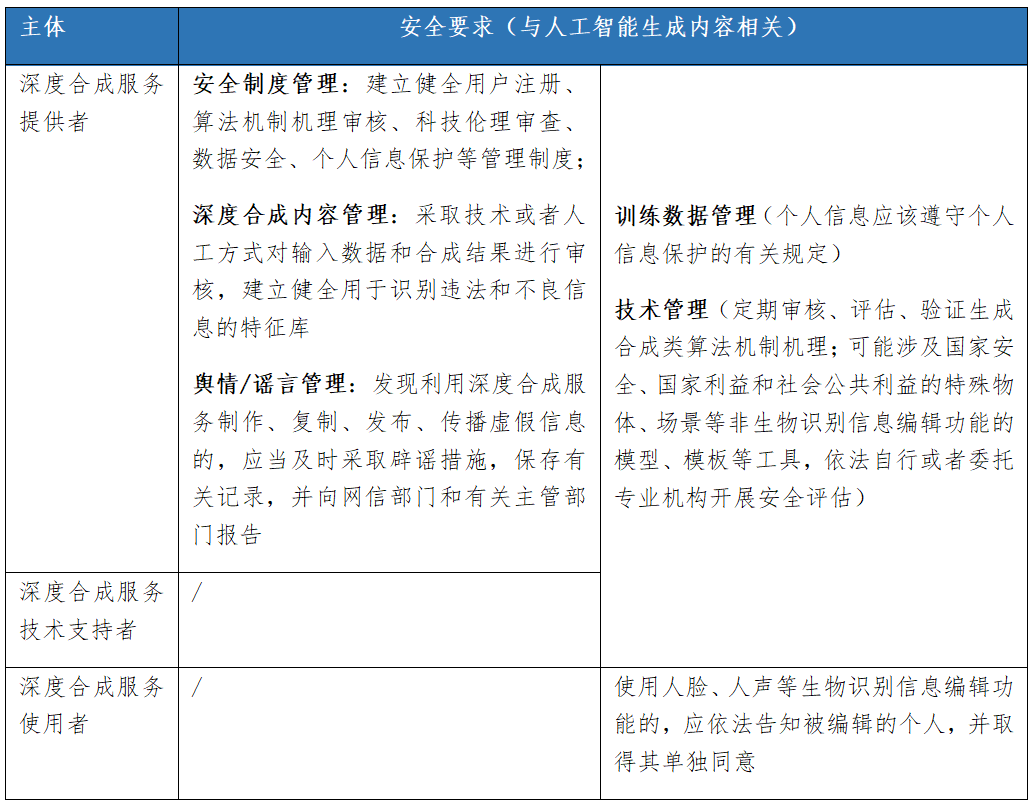
整体来看,虽然国内外暂无直接以AIGC为关键词的立法,但鉴于AIGC以人工智能技术为基础,是人工智能应用发展的一个分支,因此现有的人工智能监管体系也基本适用于AIGC,可作为重点参考。
人工智能和隐私的关键性重叠
如上所述,多个法律领域对于AIGC相关应用都有一定要求,而在隐私保护领域,一方面,AI相关的可解释性、公平性、安全性和问责制在隐私法律法规中也有所体现;另一方面,AI成熟度的提高也离不开组织在隐私问题上的努力。可以说,AIGC发展路径下,AI和隐私保护有着关键性的重叠。
目前,我国对于AIGC涉及的隐私问题,主要可以参考《个人信息保护法》《数据安全法》以及《数据出境安全评估办法》等法律法规。
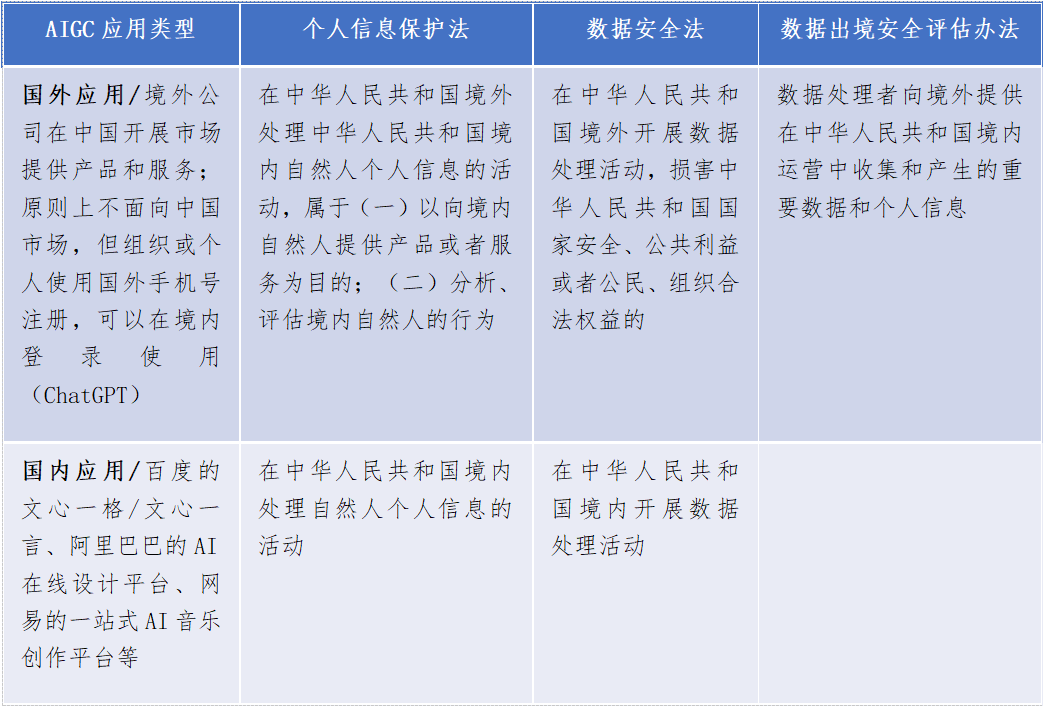
AIGC数据处理场景及对应的隐私风险
以ChatGPT为例,作为人工智能生成内容的热门应用,ChatGPT在模型训练阶段、应用运行阶段涉及海量数据的处理。
模型的成熟度以及生成内容的质量,都与训练数据高度相关。与此同时,训练数据集所包含的隐私风险也将映射到生成内容上。
阶段1:模型训练阶段
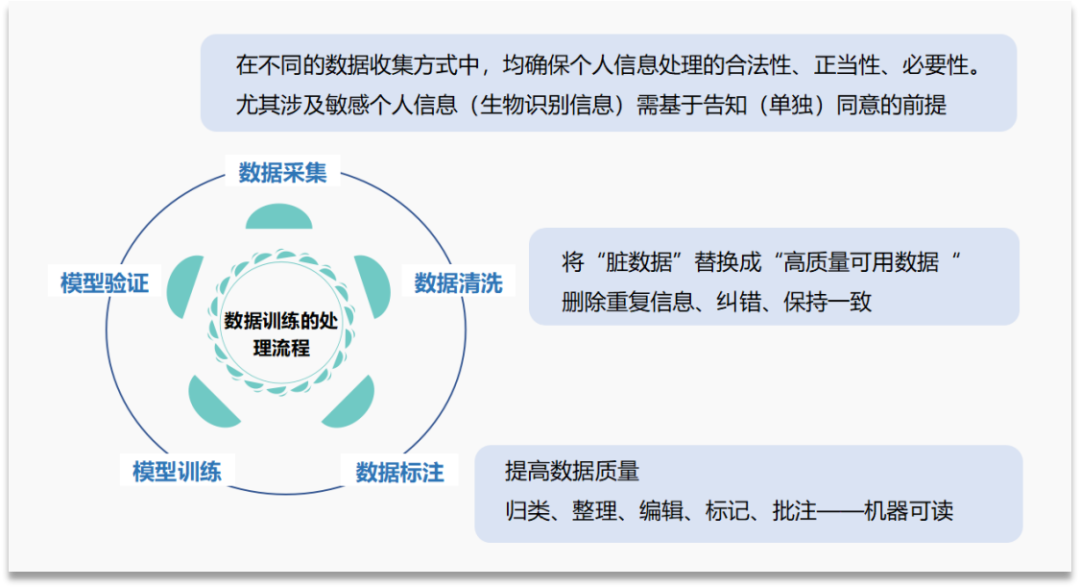
数据训练的处理流程包括:数据采集、数据清洗、数据标注、模型训练、模型验证、实现目标。所谓训练数据,是指“用于训练 AI 模型,使其做出正确判断的已标注数据/基准数据集”。
训练数据的风险集中在数据采集阶段,即数据处理者在处理训练数据中的个人信息前,是否尽到告知同意的基本责任,确保个人信息处理的合法性、正当性、必要性。数据清洗阶段和数据标注阶段,是将收集到的数据进一步处理成机器可读、便于训练的训练数据,这一阶段对于数据的审核和梳理,也是进一步缓释训练数据风险的补充措施,即审核数据集中是否包含大量可识别的个人信息或敏感个人信息。
当前,训练数据来源可以分为两类,一是网络数据,二是合成数据。

网络数据的来源包括:
①采集物理世界的个人信息从而形成网络数据,常见的是动作捕捉(Motion Capture)数据,即通过实时跟踪和记录自然人(被测试者)的身体运动信息、面部表情,将其转化为网络数据,用于虚拟人生成等领域。由于动捕数据包含个人身体动作、姿势和行为等信息,可以用于分析个人身体特征,因此也是个人信息。针对这一数据类型,主要通过合同方式,基于个人信息主体的授权同意,实现合法合规处理。
②直接采集互联网上的数据,一方面是直接获取开放的公共数据,另一方面是通过爬虫方式搜集网络数据。前者参考《上海市数据条例》,公共数据不包含个人信息、个人隐私,风险低;后者使用技术手段获取网络数据,考虑到爬虫所爬取的内容类型(如包含大量个人信息及商业数据等)及其对于目标业务和站点所带来的影响,可能存在违法风险。
③数据交易,通过B2B交易的方式向数据提供商购买数据,或依托于地方数据交易所进行场内交易。这一数据源的责任主要落实在数据交易中介、数据提供方,要求其对于所交易的数据中的个人信息进行保护。
当前,由于训练数据需求庞大,以GPT-3模型为例,其在训练阶段使用了多达45TB的数据。近几年,随着AI生成技术的发展,可以预测有效网络数据的增长将跟不上训练模型所需数据量的增速,与此同时数据获取的成本也不断上涨,因此合成类数据(Synthetic Data)开始进入市场。

以人脸数据为例,如果将一个自然人所能提供的人脸数据设为1,那么通过合成、编辑等功能,将基础的人脸数据进行调整(五官或表情),可以实现10或者100个人脸数据,大大降低训练数据的成本和获取难度。合成数据也需进行个人信息保护,根据《互联网信息服务深度合成管理规定》,在使用生物识别信息编辑功能前,依法告知被编辑的个人,并取得其单独同意。
阶段2:AIGC应用运行阶段
AIGC应用部署后,可以实现人机之间的交互。用户在输入页面填写信息,从而获得人工智能生成的内容,比如一段文字、一幅图像、一个蛋白质三维结构。当数以亿计的使用者都在实时与AIGC进行交互时,使用者输入的数据去了哪里?人工智能输出的数据又会包含什么风险?
以境外应用为例,当中国境内使用者在输入页面填入信息后,信息会传输至服务提供者的境外所在地或境外数据中心,再由应用反馈回复。这一交互过程中,AIGC主要涉及:
INVOLVE
1、个人存在将(敏感)个人信息传输至AIGC的情况,AIGC是否针对个人信息的收集、存储进行事前告知同意?
2、组织出于数据分析、信息统计等目的,存在将其收集的一定规模的(敏感)个人信息(比如包含姓名、电话等信息的员工信息表)传输至AIGC的情况,是否构成事实上的数据出境?
3、AIGC输出的内容,其中是否可能因为训练数据的问题,导致仍然存在可识别或可再识别的个人信息,即AIGC的技术支持者和服务提供者造成个人信息泄露的情形?
阶段3:AIGC模型再训练阶段
人机之间的交互所产生的数据,可能被用于未来模型的迭代训练,其中也会涉及大量个人信息。因此,AIGC服务提供者在个人或组织使用应用前,需将这一情形进行事前告知并取得单独同意。
综合AIGC数据处理过程中的3个主要情形,围绕隐私问题,可以依循现有的个人信息保护相关规定,不过仍然需要针对AIGC(人工智能)全流程的个人信息保护的综合性立法,从而促进产业安全合规发展。
AIGC发展及合规建议
去年年底以来,中共中央、国务院印发“数据二十条”、《数字中国建设整体布局规划》,国务院机构改革方案提出成立国家数据局、重新组建科学技术部。一系列密集的行动透露出我国将“数据要素供给”“数据安全治理”的重要程度再度提升的信号。
基于“鼓励AIGC产业创新发展,同时在发展中合规”的目的,拟对产业发展提出几点建议:
1.在规范主体上,构建AIGC服务提供者(提供应用或服务)、技术支持者(提供算法等人工智能技术)、服务使用者(使用AIGC的个人或组织)三方权责机制。
2.在规范内容上,基于现有的算法及深度合成内容监管基础,进一步围绕AIGC形成综合性立法。一是根据算法应用场景(如生物医疗领域、自动驾驶领域等不同领域),二是根据生成内容的类型(文本/图像/三维模型/音频/视频/代码等),依次形成AIGC风险分级分类管理体系,并对涉及人脸等敏感个人信息的高风险领域,定期开展数据安全能力评估。
3.实现训练数据全生命周期管理。对于大规模训练数据的收集、存储、使用全生命周期进行规范,尤其是加强个人信息、重要数据的保护。此外,进一步加强对于训练数据提供商的约束,要求其对于数据来源、数据交易及使用进行全流程安全监测。
4.促进数据要素流转交易。基于AIGC应用场景持续释放需求,需加快数据供给,一方面推动数据上链托管、加快场内场外数据交易流转,另一方面可以针对特定训练数据需求,有条件开放对应公共数据。
5.鼓励发展合成数据产业。出于提升数据多样性、提高训练数据质量,降低数据合规成本、模型训练成本的考虑,加快发展合成数据,包括生物可识别信息数据(用于虚拟人训练的表情、动作、声音的多模态数据)、文字/图像等非结构化数据(用于字体设计、视觉设计的数据)。
作者:周雪静 上海赛博网络安全产业创新研究院高级研究员
「声明:本文来自网络,版权归原作者所有。文章内容仅代表作者独立观点,不代表GetTrust立场,转载目的在于传递更多信息。如有侵权,请联系删除」
相关推荐: 上海:进一步做好股权变更登记个人所得税完税凭证查验服务工作
据国家税务总局上海市税务局网站消息,11月28日,国家税务总局上海市税务局、上海市市场监督管理局两部门联合发布《关于进一步做好股权变更登记个人所得税完税凭证查验服务工作的通告》(以下简称《通告》),《通告》明确,根据《中华人民共和国个人所得税法》及其实施条例、…