原文标题:Detection of Inconsistencies in Privacy Practices of Browser Extensions
原文作者:Duc Bui, Brian Tang, and Kang G. Shin
发表期刊:2023 IEEE Symposium on Security and Privacy
原文链接:https://www.computer.org/csdl/proceedings-article/sp/2023/933600a037
笔记作者:LaReina@SecQuan
笔记小编:ourren@SecQuan
1 研究介绍
浏览器扩展被要求通过各种形式向用户公开他们的隐私政策,但是其所声明的隐私策略可能与实际收集的用户数据之间存在差别。为了检测这种不一致,作者提出了自动化检测框架ExtPrivA,它提取浏览器扩展在隐私政策文档和Dashboard中声称的隐私策略,然后进行动态分析,模拟用户交互以触发扩展的功能,并分析网络请求的发起者,以准确提取扩展从浏览器传输到外部服务器的用户数据,将其和声明的隐私策略对比,检查是否存在不一致。
ExtPrivA的分析流程图如图1所示,总体分为两个阶段,阶段一为人工提取本体,阶段二为自动化持续分析。
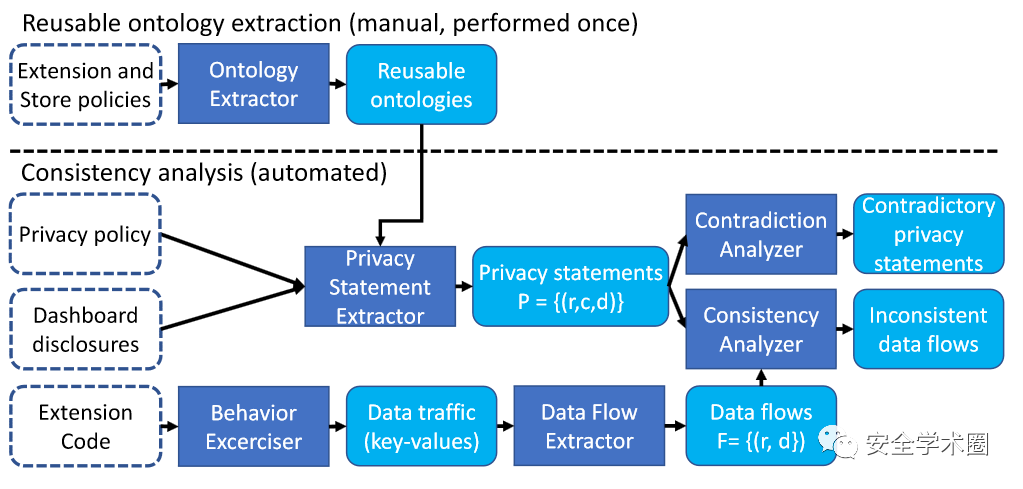 图1 分析流程图
图1 分析流程图
2 分析浏览器扩展的隐私策略
首先,为了简化对隐私策略的分析,作者仅分析与数据收集相关的隐私声明,并将一个隐私声明定义为 ,其中 是数据接收者,表示是否有收集数据行为, 表示数据类型。浏览器扩展与隐私策略相关的地方有两处,分别是Dashboard和隐私策略文档。
2.1 分析Dashboard中的隐私声明
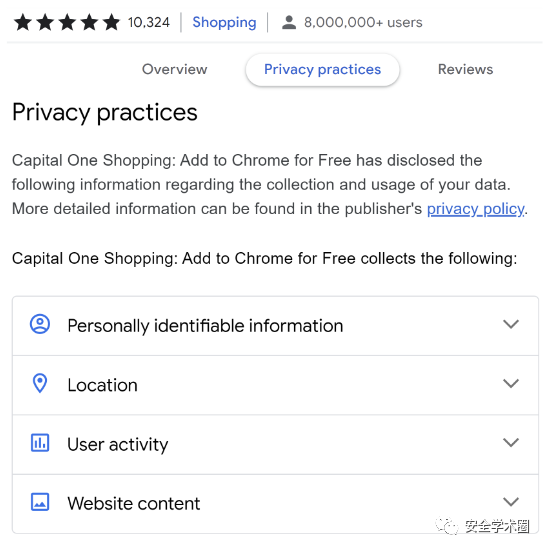 图2 Dashboard中的隐私声明示例
图2 Dashboard中的隐私声明示例
Dashbord中的隐私声明是基于一个公共模板的,如图2所示。作者用集合 来表示扩展声明要收集的数据类型, 为扩展能收集的所有数据类型,则集合U = T\D = {d′i | d′i ∈ T ∧ d′i 可表示扩展不会收集的数据类型。因此可以得到扩展的隐私声明表示为:
2.2 分析自由格式的隐私策略文档
隐私策略文档是自由文本格式的。ExtPrivA采用了一个名为PurPliance的隐私策略分析工具来从句子中提取隐私声明,系统首先识别句子中的“收集”“共享”“使用”类动词,然后通过语义角色标注提取每个动词语义的参数(如主题和对象等)。通过命名实体识别模型来从动词的的对象中提取数据类型。但是由于目前的基于句子的隐私策略分析技术无法分辨每个声明的作用范围,即无法确定该声明是针对网站的还是扩展的,因此作者排除了没有提到关键字“扩展”的声明语句来减少假阳性。
3 动态分析扩展执行时的数据收集行为
3.1 触发扩展的数据收集行为
ExtPrivA首先从扩展的manifest中提取该扩展能够访问的URL模式,并为为每个URL模式生成与之匹配的可能的候选URL。然后构造蜜页和与真实网页作为测试页面,通过用户交互仿真(如文本选择、鼠标动作、键盘输入、表格提交等)来触发扩展的数据收集功能。
3.2 数据流量分析
由于HTTP请求不区分来自扩展和来自网页,因此提取来自扩展的数据流量有一定的挑战。ExtPrivA通过分析请求发起程序(Initiator)和HTTP Origin header来提取扩展的数据流量。
首先,ExtPrivA利用Chrome开发者工具中提供的网络活动中的Initiator信息。如果一个脚本URL以chrome-extension格式为前缀并与该扩展ID匹配,则该流量是由扩展发起的。其次,ExtPrivA检测HTTP Origin header,如果HTTP请求是由一个扩展发起的,则Origin header会被设为chromeextensions://。在提取到扩展的数据流量后,ExtPrivA将其HTTP请求解析为键值对。
3.3 从原始数据流量中提取数据流
作者将数据流定义为 ,其中 示数据接收方, 表示数据类型。作者选择提取四种不依赖于上下文的高级数据类型,分别是网站内容、网站历史、位置和用户活动,在此基础上又细分为11个低级子类。从键值对中提取数据类型的问题可以被建模为一个分类问题,作者设计了基于模式匹配规则的分类器。
3.4 检测不一致性
ExtPrivA通过分析第二节中提取的隐私策略和第三节中提取的数据流之间的不一致性,来检测扩展声明的隐私策略和实际的数据收集行为之间的矛盾。但由于数据流和隐私策略的术语和粒度表示不同,因此ExtPrivA利用数据类型和接收实体的本体来表示术语之间的关系,以进行语句和流之间的逻辑比较。
4 实验与分析
4.1 数据集作者在谷歌商店中爬取了35,316个提供了隐私政策文档URL的扩展,但其中12,484个扩展没有Dashboard隐私声明。ExtPrivA下载并提取了27,309个扩展的隐私政策的纯文本版本,其余隐私政策URL无法访问。经过隐私策略提取后,得到的数据类型分布如表1所示。
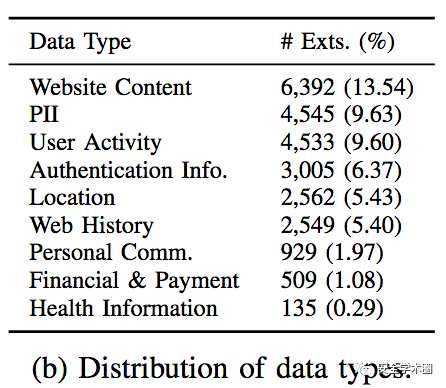 表1 Dashboard隐私数据类型分布
表1 Dashboard隐私数据类型分布
4.2 动态分析数据收集行为
作者通过蜜页和真实网页来触发每个扩展的功能,捕获其网络流量,提取了从3,904个扩展发送到3,280个唯一主机和6902个外部服务器端点的680,923个键值对,每个端点是一个主机和一个路径的组合。最常见的主机是www.google-analytics.com (11.77%)。为了激活扩展的功能,ExtPrivA平均访问了5.1个候选URL。
ExtPrivA从数据流量键值对中,为1,002个扩展接收到的数据类型抽取了1,706条唯一数据流。每个扩展平均收集1.7个数据类型。从扩展中提取的最常见的数据类型是当前访问的网页的URL和Hostname,属于Web History高级数据类型。这些数据类型是隐私敏感的,因为可以用于构建用户的网页浏览习惯。表2显示了抽取的数据类型在扩展上的分布。
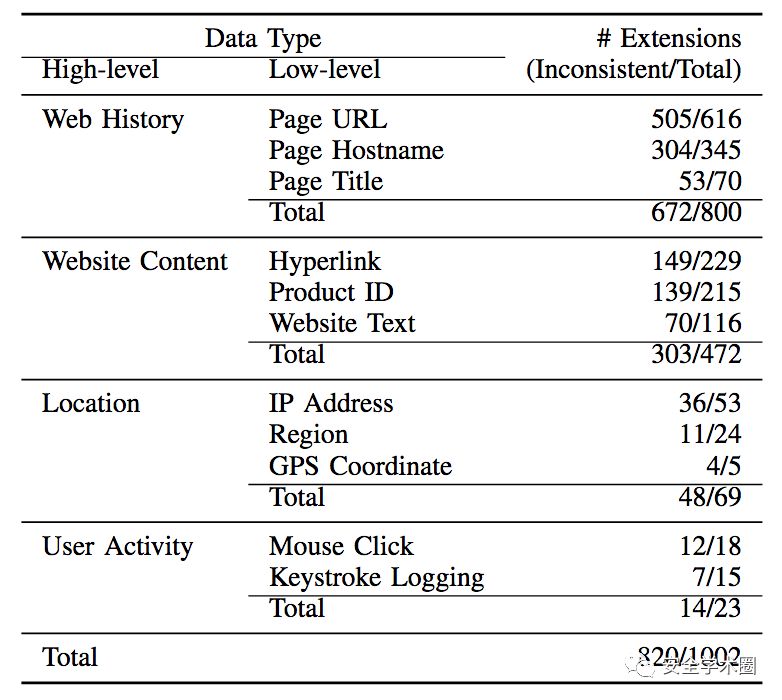 表2 数据类型在扩展上的分布
表2 数据类型在扩展上的分布
如表3所示,最常见的接收者类型是扩展自身的主机(第一方)和分析提供者。其中最常见的第一方和分析主机分别是bar.maxtrigger.com和www.google-analytics.com。在线跟踪器和广告网络相比之下则不太常见。
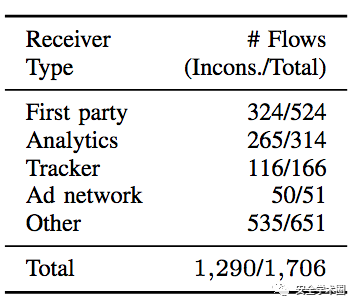 表3 数据接收者类型在不同数据流上的分布
表3 数据接收者类型在不同数据流上的分布
作者还分析了扩展收集数据的目的,结果显示其主要目的是用于改进或提供服务,最常见的数据类型是网站内容(超链接和产品ID)和Web历史(当前访问页面的URL)。图3给出了数据使用目的的分解图。
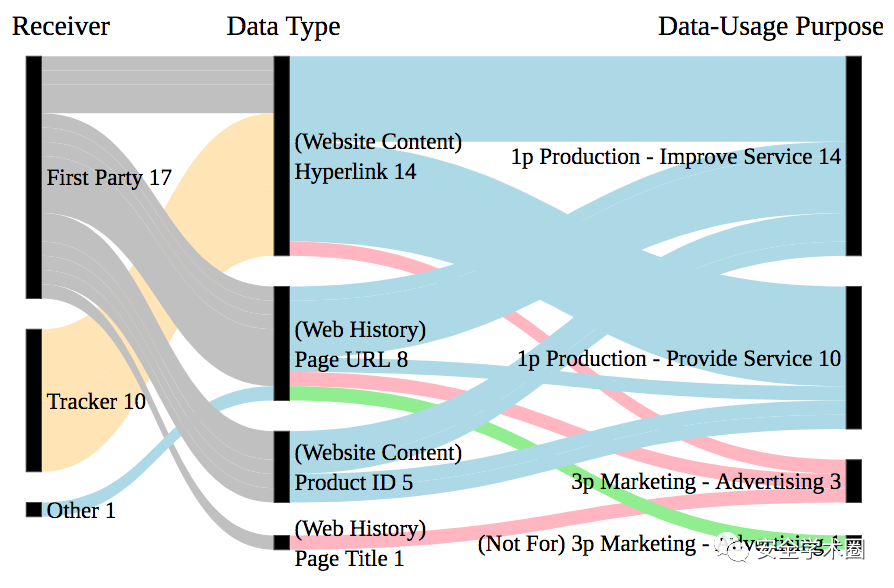 图3 数据收集目的分解图(1p和3p分别指第一方和第三方)
图3 数据收集目的分解图(1p和3p分别指第一方和第三方)
4.3 发现
(1)大量扩展未能在隐私策略中完全声明其向用户收集的数据类型:ExtPrivA检测到820个扩展的数据流与其Dashboard中声明的不一致,其用户量超过84.6M,这些扩展占抽取了数据流的扩展的81.84 %。这一结果凸显了Chrome Web Store上不完整的隐私声明给大量用户带来的高隐私风险。
(2)Dashboard隐私声明与隐私政策文档之间存在矛盾语句:ExtPrivA在17.22 %的扩展隐私政策中检测到525对矛盾隐私语句。最常见(73.9%)的矛盾类型包括在Dashboard中声明不收集任何数据而在隐私政策文档中却声称收集某些数据。
(3)潜在的原因:导致扩展出现隐私声明和收集行为不一致的原因有,声明较少的收集数据类型可能会缩短Store的安全审查和发布扩展的时间。例如,71.57%的扩展声明自己”没有收集或使用任何用户数据”。此外,在没有声明的情况下收集的最常见的数据类型是Web History,它发生在672 / 1002个扩展中,因为不声明收集敏感的历史记录数据类型可以避免用户产生怀疑,提高用户的安装率。
4.5 检测效果评估
作者通过验证随机选取样本的正确性来评估系统精度。
(1)dashboard与隐私政策文档的矛盾检测precision达到91.7 %。在56个扩展的60个随机选择的语句对中,只有5个为假阳性。其中一些假阳性是由于缺乏共指消解等跨句分析造成的。
(2)数据类型提取的precision达到93.3 %。其中精准度最低的是Hyperlink数据类型,表示当前访问的网页的超链接的集合,因为在某些情况下,链接是由扩展插入的,而不是原始的网页内容。
(3)端到端一致性检测的precision为85%。大部分误报是由于扩展并未收集数据的回调函数被包括在网络流量的发起者中了,例如,一个扩展安装了一个HTTP请求事件处理程序来检查HTTP请求中URL pattern是否出现,但它没有进行任何数据收集。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表GetTrust立场,转载目的在于传递更多信息。如有侵权,请联系删除。